 |
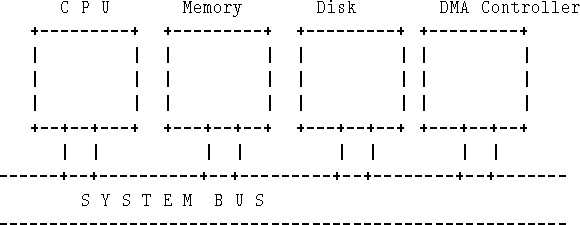
Figure 8.1 shows the hardware of a typical computer system. During the first part of the course, we have seen that:
- that main-memory is a large collection of `pigeon-holes' each of which can hold one number; each number can represent:
Without software, the system in Figure 8.1 just sits there quietly, doing nothing!. It must be programmed with appropriate software.
Roughly speaking, software can be divided into two categories:
The divide, between system and application, can be somewhat blurred. In general, the more general purpose and ordinary the function performed - like copying or deleting files, or compiling or assembling programs - the closer to system software; the more special purpose - like a database management system - the closer to application category.
Originally, the system software was likely to be developed by the computer hardware manufacturer; however, since the 1980s, the PC revolution has turned this on its head. This chapter is concerned primarily with the operating system - which is definitely system software.
The system software, particularly the operating system, mediates between the user (and the application software) and the hardware. Thus, though in reality (hardware) a disk may be lots of circles with bits (1 or 0) arranged along their circumference, that is very difficult for a programmer or user to handle. For example, instead of clicking on FILE/SAVE, you would have to concoct some machine code to do: `save the first 128 bytes on circle 22, head 2, sector 4 and save the second 128 bytes on ...', see Chapter 9, all the time checking, and updating your list of occupied sectors. The operating system handles the whole filing system for you. You just give the file name and it does the rest.
From the point of view of a user at the keyboard, the operating system makes the computer act `intelligent' and alive. From the programmer point of view, it provides several services. The user of the service can be an application program - via invocation of a service function, e.g. System.output.println(); - or a human user - via the operating systems human-interface,
With Windows NT and Linux, we are moving away from single-user operating systems to multi-tasking - where, for example, the user can set the computer to compiling a large file, while he/she starts to edit another file.
Microsoft Windows-95/98 offers some multi-tasking features. Windows NT is truly multi-tasking.
Since the late 1960s, operating systems on large computers have been multi-user; they allow a large number of users to use a single computer at one time, with each having the sensation of being the sole user of the machine. In the multi-user case, in addition to normal operating system duties, the operating system must:
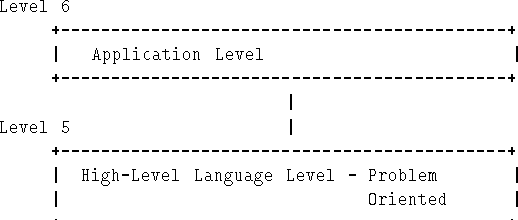
Recall, from Chapter 1, the multilevel view of a computer. At each level there is a different virtual machine which obeys its own language.Figure 8.2 recalls this view.
Except for levels 0 and 1 each level is, in fact, virtual, in the sense that it is created by a computer program or interpreter.
The operating system also provides a higher-level abstraction for parts of the underlying hardware, e.g. a hierarchical file directory structure as an abstraction for a complex system of spinning disks, controllers etc.
It would be a good idea, at this stage, for you to get these different levels clear in your head. You should also convince yourself of the value of working at the highest level possible - employing the highest level of abstraction possible. If you need more convincing, consider reworking your last Java assignment in assembly language! Employing a higher level of abstraction is like a walker being able to take 10, 20 or maybe 500 steps at a time - for no extra effort; or, like travelling across the Atlantic by air, rather than swimming or rowing a boat.
See [Tanenbaum, 1999] or [Tanenbaum, 1990] pages 1 to 7.
[Tanenbaum, 1999] or [Tanenbaum, 1990] pages 8 to 25.
Computers were treated as electronic instruments and could only be programmed using binary codes (machine code). The methods of inserting the codes varied: switches, paper tape, punched cards or, at the beginning, patched in with wires which connected High or Low voltages to indicate `1' or '0'.
By this time (say 1959) there were compliers - like FORTRAN. Users would run their own programs - much like users of personal computers do nowadays. Users booked the machine for (say) 1/2 hour at a time. Programs were prepared off-line - onto punched cards - computers were too expensive for such menial tasks.
It was up to the new user to load whatever program was required onto the machine - from cards; executable and source code were both on cards.
[Tanenbaum, 1999] or [Tanenbaum, 1990] p. 8, 9 describes a typical session, in which the user tries out his/her latest FORTRAN (source) program.
You may be able to imagine the following scenario if you think of an organisation with a single small, slow microcomputer, with one floppy drive, no hard disk and no resident operating system.
Note. if the compiler required two or more passes, then steps 2 and 3 had to be repeated for the requisite number of passes - with a separate compiler deck for each.
Clearly, much time was wasted:
All this on a machine that costed a few million pounds.
Side-bar: In 1960, an average programmer salary was about £1500, a computer cost around £1,500,000: ratio person annual salary to computer capital cost, 1 to 1000. Today, salary £30,000, powerful PC, £1000: ratio 30 to 1. Thus, compared to 1960, computers aretimes the cost; or programmers 30,000 times more expensive!
The next stage was to hire an operator. The operator performed all interaction with the computer. Users submitted `jobs' on cards, and received the results back on line printer paper.
The operator was more skilled and quicker at operating the computer.
Also, similar jobs could be batched, e.g. all the FORTRAN compilations - allowing the FORTRAN compiler program to be loaded only once, followed by all the linking, etc.
Furthermore, the operator could assert priority:
These are all feature that can be seen in modern operating systems.
Reading cards was not much of a job for a X million pound computer!
Better to create - on a cheaper satellite machine - a magnetic tape, that contained many jobs, and get the expensive machine to work its way through the tape. Maybe there were two tape decks - one to replace the card input, one to replace the card output. Also the system software (compiler, linker/loader) could be kept on a tape.
Most significant, however, from an operating systems point of view, was the addition of a small resident monitor program which remained in memory all the time and which ran each job in turn. This was the great-grandfather of today's OSs. The term operating system crept in because of the similarity of the resident monitor's role to that of a human operator.
The previous instructions to the operator (in English) now had to be coded for the resident monitor. These instructions had to be punched on cards -- a typical convention was to precede resident monitor commands with an asterisk, `*', to distinguish them from source program statements, or data; i.e. the resident monitor had a rudimentary command language interpreter.
A typical resident monitor was IBM's FORTRAN Monitor System - FMS -- that ran on the IBM 709.
Early resident monitor systems used polled input-output, see chapter 7, to read from and write to their magnetic tapes; thus, when they needed input, or needed to output, the CPU gave up all other activity and attended to the tape. Polled i-o is very inefficient inefficient; most of the time is wasted waiting for `status-ready' and things like that. Therefore, the next elaboration was to add software to the resident monitor to allow it, simultaneously, to read from tape, do CPU processing, and, perhaps, write to an output tape or printer.
For slower devices like tapes, interrupt driven device drivers, see chapter 7, were sufficient.
Eventually, disks were added to the main machine. The off-line tape preparation machines would be dispensed with, since the card jobs could be read-in on the main machine (using interrupts) and placed on disk to await execution. In addition, running jobs could write to disk files (faster), with the disk files being printed fairly independently.
A primitive scheduler was added to the resident monitor:
Operators tasks are now limited to:
This mode of running was called spooling: simultaneous peripheral operations on line - spool.
The operation is somewhat evocative of a spool of thread:
Spooling systems are the grand-daddies of modern OSs.
Nevertheless, spooling doesn't totally remove I/O waiting. Consider a program which is doing a stock update, and the stock files is on mag. tape: very often the CPU has to issue a read-from-tape and can do nothing until the data arrives.
The job is then said to be input-output bound - no amount of interrupt handling can help in this case.
Multiprogramming comes to the rescue.
If the memory is big enough - or the jobs small enough:
(*) However, using only the simple rule: CPU bound jobs are favoured. The problem with this rule is that a big number crunching program with no I/O could hog the CPU for ever.
Thus, the scheduler becomes a good deal more complicated. CPU time is one of the main resources that jobs are in competition for - implementing policies for sharing such resources is a big part of an operating system's task.
Multiprogramming also introduces competition for memory space. Also, the resident monitor and other programs must be protected from malicious or faulty programs that try to write to parts of memory not owned by them.
What we have just described is called batch multiprogramming: each user job may be considered to batch together a set of steps - e.g. compile-pass1 ...-pass2 ...link ...run. Each step is independent - provided its results are stored safely on disk.
Thus, the resident monitor can schedule each (sub)task independently.
The term process is used to mean an executing program that performs a subtask; more about processes later.
At this stage the resident monitor has become a true operating system, albeit still batch.
In addition to queuing and running processes, the OS provides services to the process via service calls. Programs & processes can no longer access input-output devices directly - they must - in the terminology of multi-level machines - execute an OS machine level instruction that does that for them.
Of course, two processes may require the same resource at the same time, e.g. tape, printer; CPU time and memory are also resources that are in heavy demand. The business of granting resources in a fair way is not a trivial one.
The batch multiprogramming described above was fine for the computers - but not for people - if programmers can be considered people, which, in organisations, is rare! In developing a program you could spot an error five seconds after getting your batch job back from the machine, and have to wait a day to get another try. Programmers needed quicker response.
Interactive multiprogramming or time-sharing was the solution.
Instead of interacting, indirectly, via cards and printout, each user has an on-line interactive terminal. They also have access to the disk - perhaps their own directory - to store programs and data between sessions.
The whole basis of time-sharing is that there may be 5, 10 or 100 users connected to a single computer - with one CPU - with each of them getting the impression that she/he is the sole occupant. Of course, if all these users are running heavily CPU intensive programs (number crunching), the impression of having a machine to yourself quickly subsides. However, that will rarely be the case; at any instant, out of 20 connected users, 7 might be editing (requires little or no CPU time), 10 might be thinking about what to do next, and only 3 doing anything that really exercises the CPU -- e.g. compiling or running programs.
Incidentally, operating systems have ways of discouraging heavy CPU and memory users from peak interactive times. For these users, a form of batch service is offered. The user submits a job to a batch queue much the same way as before - except the job is specified (1) interactively (2) in a disk file, and (3) the inputs and outputs also use disk files. The batch queue is treated differently from the queue associated with the interactive users - it is probably only given a chance at night, or when the interactive use gets very slack.
Massachusetts Institute of Technology (MIT) were the first to demonstrate a time-sharing system - about 1960; that was CTSS. It ran on a converted IBM 7094. But, on machines whose hardware was meant to run one program/user at a time, time-sharing was not easy -- see later.
The next step was MIT, Bell Labs. and General Electric co-operating in producing MULTICS (MULTiplexed Information and Computing Service). MULTICS was way ahead of its time. For the companies involved, maybe too far ahead, for it was costly to produce, and was not commercially successful.
But, MULTICS was enormously influential on the technical development of operating systems. MULTICS begat UNIX. Scratch the surface of most modern operating systems and you will find some MULTICS or UNIX influence.
Up to 1961 computers were a bit like electricity generating plants -- they took up whole buildings or, at least, floors or rooms. They cost $millions.
In 1961 Digital Equipment Corporation (DEC) introduced the PDP-1. The PDP-1 had 4K of 18-bit words. It cost a mere $ 120,000. For some jobs it was nearly as fast as an IBM 7094 - the 7094 cost $2 million). Personal computing was on the horizon.
A whole family of PDPs, so-called mini-computers were developed, leading to the PDP-8 - the first true personal, or, at least, laboratory computer - and the PDP-11.
After Bell Labs. dropped out of the MULTICS project, Ken Thompson, one of the MULTICS team at Bell Labs., wrote a single user version of MULTICS for a PDP-7. It was written in assembly language. It was called UNIX - as a pun on Multics.
Note that the PDP-7 had 4K memory.
Yet this early UNIX featured:
Next step: UNIX was ported onto a PDP-11/20 and later a PDP-11/45.
But, besides its power and elegance, the next step was to ensure UNIX's fame and fortune. Dennis Ritchie joined the team and developed the C programming language. Around 1972, a new version of UNIX was written, almost entirely in C. Now UNIX could be ported onto any machine that had a C compiler.
This section summarises OS history in the form of generations, see [Tanenbaum, 1990] or [Tanenbaum, 1999].
If each task required nothing but CPU time then multiprogramming would have little advantage over running tasks consecutively. Figure 8.3 shows two tasks labelled A and B, each of which requires different resources (VDU, disk and CPU) in the order in which they are shown.
If task A were allowed to run to completion before task B was started, valuable processing time would be wasted. We show below how the tasks may be scheduled to make more efficient use of resources, see Figure 8.4.
From Figure 8.3, it can be seen that, if each step takes one unit of time, and they are done entirely sequentially, then the total time is 10 steps. Contrast Figure 8.4 - timeshared -, which takes just 6 steps.
It is worth noting that if the CPU is to be available to one task while another is accessing a disk or using a printer, then these devices must be capable of autonomous operation, i.e. they must either be able to transfer data by DMA (direct memory access, see chapter 7) -- without the active intervention of the CPU or must be able to receive a chunk of data at high speed from the CPU and process it at their leisure.
The next chapter will look at some of the details of how a time-sharing operating system schedules many tasks, and allocates resources to them in a fair or otherwise optimal manner.
This comes down to: