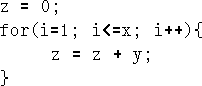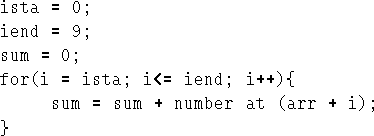 |
The instruction set (Mac-1a) introduced in chapter 6 was severely limited - particularly in its inability to call subprograms. We now extend our coverage to the remainder of the Mac-1 instruction set, and attempt some more ambitious programs.
Firstly, we will introduce the additional instructions - especially those based on the stack; we will explain the purpose of a stack and its use for handling subprograms.
In addition, we will describe the memory addressing modes found on most general purpose computers. Next, we will show how some more real programs can be constructed, from simple three or four liners, to subroutines, input-output and interrupts.
Although this chapter is entirely about Mac-1, the presentation is such that the principles of general-purpose computers are emphasised. Thus, someone who follows this chapter will have little difficulty in understanding Motorola 68000, Intel 80x86 series, or virtually any conventional computer.
In a computer, memory locations can hold instructions or data. In addition, as we shall see the data can be interpreted either as a plain value, e.g. 100, or as an address or reference to another data item. Those of who are familiar with C/C++ will recognise pointers; and Java people will recognise references.
In general, machine instructions usually take zero, one, or two
operands (e.g. in lodd a0; a0 is the single operand;
lodd is the operation;
Actually Mac-1 has no multi-operand instructions. For a start, it is an
accumulator machine, i.e. in instructions like addd, lodd,
the second - implicit - operand is AC, the accumulator.
Operands can be data, or can refer to data - i.e. address of data, or
can be labels - which translate to addresses - of instructions, e.g. for
jumps.
The question of addressing is concerned with how operands are interpreted. In the case of data the operand can be:
LOCO 5; 0111 0000
0000 0101;
0000 0101 0000 0001 ; lodd 501;
If memory cell 501 contains `7'
+--------------+
501: | ... 0111 |
+--------------+
it is the `7' that gets loaded into the AC.
xxxx
0101 0000 0001 lodi 501; if memory cell 501 contains `50a', and
memory cell 50a contains `3', we have:
+--------------+
501: | 50a |
+--------------+
...
+--------------+
50a: | 3 |
+--------------+
and it is the `3' that gets loaded into the AC.
lodd 1230
loop: addi 1230+SI ;ac<- [ac]+m[1230+si]
inc SI
...test for end
jump loop
Of course, because Mac-1 has no index registers, I have had to invent one (SI), and an addressing mode for add: addi - add direct using SI as an index; also I had to invent an `increment instruction. Indexing is a bit like running your finger along a table of figures. The instructions 'lodl'...'subl' introduced below are a bit like indexed - but they use a very special index register called the stack-pointer (SP).
Addressing modes look complicated, but if you are careful to analyse what a construct means - by drawing a diagram, if necessary - then there are no real pitfalls.
Also, for those who are not specialists in assembly programming, you should keep to the simple modes and only use the complex modes when they are absolutely essential.
Figure 7.1 shows the Mac-1 instruction set extended to the full repertoire given in [Tanenbaum, 1990]; we do not bother with the binary version of the instruction - as in Figure 5.2 and Figure 6.1, since we will not be assembling programs using the additional instructions, nor writing them in machine code.
jneg x Jump on negative if ac<0 : pc <- x jnze x Jump on nonzero if ac!=0 : pc <- x
These save some of the trouble encountered using just jpos and
jzer; however, as we have seen, they are not essential.
In Mac-1, the register SP is the stack-pointer and is dedicated to maintaining the stack; the stack itself - the data pointed-to - is actually part of main-memory.
The stack is a memory into which values can be stored and from which they can be retrieved on a last-in-first-out (LIFO) basis. Ideally, you store with a PUSH and retrieve with a POP. It may help to think of an analogy such as a spring loaded canteen tray dispenser, or a bus conductor's coin dispenser; the main point is that you can only put on the top (PUSH), get from the top (TOP) or remove the value at the top (POP). In spite of its simplicity this device has a remarkably large impact on the computational capability of a computer. A stack gives us a sort-of indirect addressing and also a sort-of indexed addressing via a the stack pointer; but a stack does much more than that, it is the basis of the implementation of functions and procedures, and blocks in block-structured high-level languages. SP points to the top of the stack - i.e. to the memory location where the last value was pushed.
In the case of Mac-1, the stack grows from high memory towards low memory. PUSH increases the size of the stack by one and places a value in the new memory cell (at the top). POP exactly reverses the process, i.e.. retrieves the last value written (the top) and decreases the size of the stack. PUSH followed by POP has exactly NO effect. And, as usual with Mac-1 most things are done through the accumulator (AC); PUSH pushes the number in the AC, and POP retrieves the top of the stack into the AC.
PUSH operates as follows:
PUSH ;sp <- sp - 1 ;SP decremented, NB. this INCREASES
size of stack.
;m[sp] <- ac ;put contents of AC into the memory
cell that SP POINTS TO
POP:
POP ;ac <- m[sp] ;get contents of cell pointed to by
SP, into AC.
;sp <- sp + 1 ;decrease size of stack.
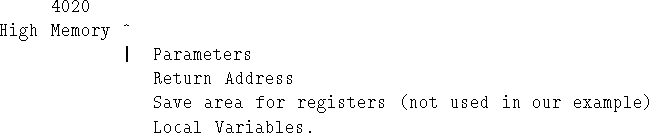
Note carefully again that the stack actually grows downwards, one word at a time - actually this is the case on a great many machines. Normally, in Mac-1 programs, we will assume that SP starts off pointing at memory cell 4020.
/(a)
lodd a0 /ac <- [a0] (=30)
push /(b)
lodd a1 /ac <- [a1] (=91)
push /(c)
pop /ac <- m[sp]; sp <- sp -1
stod a0 /(d)
pop /
stod a1 /(e)
In examples like this, to show the address of a memory cell and what it contains, we use the notation:
address: contents
500: 30
a0 500: 30
a1 501: 91
AC : ? 4018: ?
4019: ?
SP: 4020 --points to---> 4020: ?
a0 500: 30
a1 501: 91
AC : 30 4018: ?
+->4019: 30
SP: 4019 --points to--+ 4020: ?
a0 500: 30
a1 501: 91
AC : 91 +-->4018: 91
| 4019: 30
SP: 4018 --points to--+ 4020: ?
a0 500: 91
a1 501: 91
AC : 91 4018: ?
+->4019: 30
SP: 4019 --points to--+ 4020: ?
a0 500: 91
a1 501: 30
AC : 30 4018: ?
4019: ?
SP: 4020 --points to---->4020: ?
Comments:
push Push onto stack sp <- sp-1; m[sp] <- ac pop Pop off stack ac <- m[sp]; sp <- sp+1
See section 7.4.
pshi Push indirect sp <- sp-1; m[sp]<-m[ac] popi Pop indirect m[ac] <- m[sp]; sp <- sp+1
Thus, the AC is used `indirectly' - see indirect addressing mode, section 7.2; i.e. the value that is contents of the memory cell that is pointed-to by [ac] is pushed and popped.
CALL and RETN are used for CALLing subprograms (methods or functions in Java) and RETurning from them.
call x Call procedure sp<-sp-1; m[sp] <- pc; pc <- x
(get stack (save pc) (put jump
ready) address
in pc)
CALL causes all of the following to happen:
JUMP label, but the important difference
is that we remember where we were in the calling program, i.e. we must
remember where we came from, so that we can get back there again.
retn Return from proc. pc <- m[sp]; sp <- sp + 1
RETN causes all of the following to happen:
We have now introduced most of the new instructions; we wait for later sections to introduce the others. Also, we shall see in later sections more detail on how subprograms work.
This is mostly a repeat of section 5.6.
As stated earlier, there are no direct instructions for input- output; instead Mac-1a uses memory-mapped input-output, whereby some memory cells are mapped to input-output ports; for simplicity we assume that there are only two ports, one connected to a standard-input device, the other connected to a standard-output device:
We assume that each device works with bytes (i.e. 8-bits).
A read from address 0FFCHex yields a 16-bit word, with the actual data byte in the lower order byte. There is no use in reading the input port until the connected device has put the data there: so 0FFDH is used to read the input status register; the top bit (sign) of 0FFDH is set when the input data is available (DAV).
Thus, a read routine should go into a tight loop, continuously reading 0FFDHex, until it goes negative; then 0FFCHex can be read to get the data. Reading 0FFC clears 0FFD again.
Output, to 0FFE, runs along the same lines as input. A write to 0FFE will send the lower order byte to the standard-output device. The sign bit of 0FFFH signifies that the device is in a ready to receive (RDY) state; again there is no use writing data to the output port until the device is ready to read it.
test: lodd fff /read status
jpos test /not ready
jzer test /not ready
out: lodd 500
stod ffe /output
teststat: lodd fff /read status
jpos test /not ready
jzer test /not ready
out: lodd 500
stod ffe /output
given above, is unsatisfactory for many purposes; what happens, for example, if the output device is broken, or is switched off, and, as a consequence never becomes ready; the program would stay in the tight loop and the only way to stop it would be to reset/reboot.
Change the code to count its `not-ready' failures and, if this count ever reaches `maxcount' (e.g. maxcount = 100) to put -1 in AC and JUMP to label `exit'.
This section further illustrates the use of assembly language with some simple examples.
Note: in none of the following examples have I tried to optimise the code or to be clever; assembly coding is difficult enough without that.
Mac-1 has no multiply or divide - not even for integers - so we have to do it all with adds and subtracts.
Note. we will assume that the result will fit into 16-bits; Q. what general
check on the two operands will ensure this? Ans. if the multiplication is
z = x * y; then if x <= 127 and if y <=
127, the result will certainly be less than 32767, which is the largest
positive number that can be stored in 16-bit twos complement.
We will also assume, without any loss of generality that both numbers are positive; working with negative numbers adds a little housekeeping work that need not concern us now.
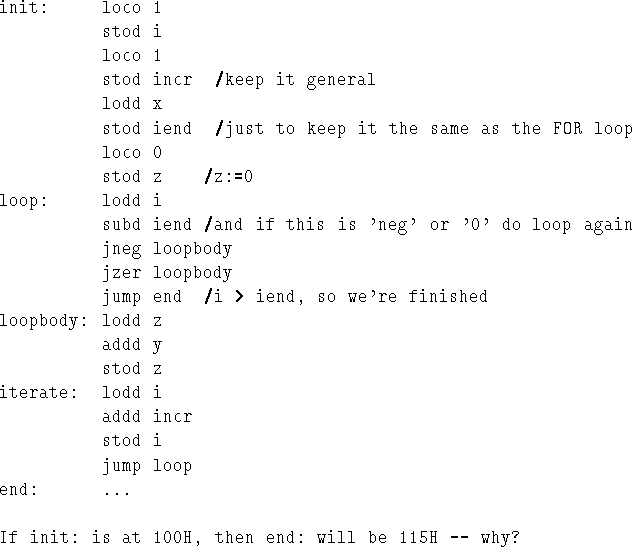
To implement z = x * y; we use the algorithm shown in
Figure 7.2,
i.e. we zero z, then add y into it x
times. Therefore, we can use most of the for loop mechanism described in
chapter 6. The assembly code is shown in Figure 7.3.
At the end (end:) the result is in z.
Again, we assume that both numbers are positive, and that it is sensible to divide them - again we will leave out some of the bullet-proofing details.
z = x / y;
We use the algorithm in Figure 7.4, i.e. we count how many times we have to subtract 'y' from 'x' to get to a remainder less than 'y'. The assembly code is shown in Figure 7.5.
At the end (end:) the result is in `z'. Of course, the result is
`integer' divide, e.g.  . You could modify this code to give you
. You could modify this code to give you
% (modulo - or `remainder after division').
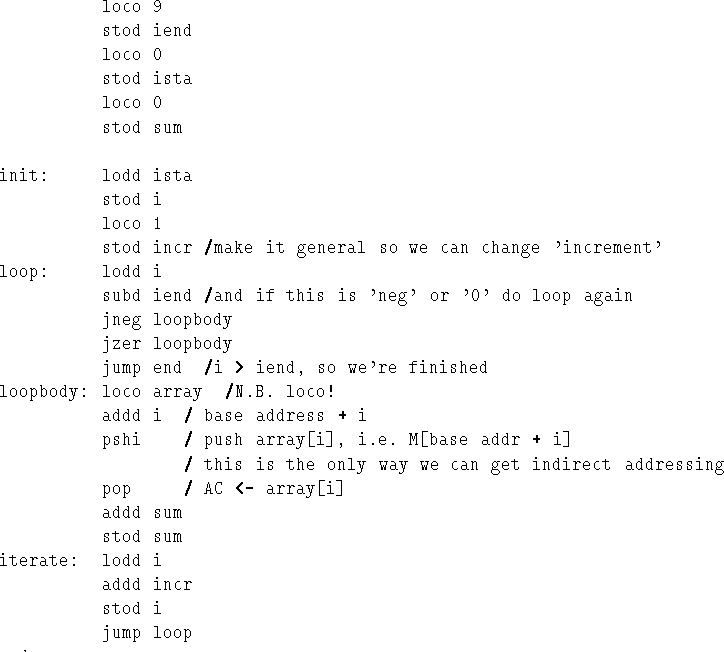
Assume that a0, a1, a2, ... a9 are stored contiguously in 500,
501, ...509, and we want to treat them as an array arr[10]; we
require to sum them and put the result in sum. We will assume that
all the numbers are sensible, i.e. that overflow isn't a problem.
We could address each of them individually:
init loco 0
addd a0
addd a1
...
addd a9
stod sum
but that wouldn't be too clever for very long arrays.
We'll use a loop, see Figure 7.6. The assembly program is shown in Figure 7.7
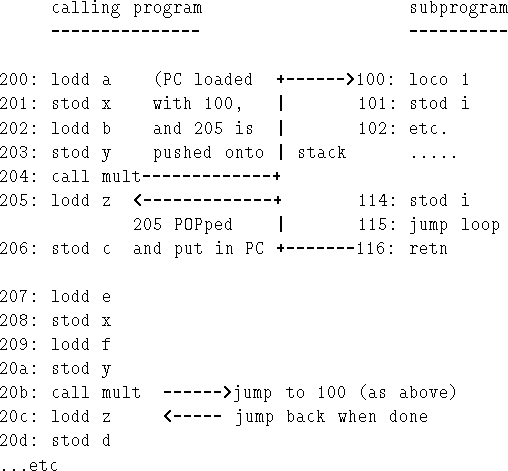
As mentioned above, CALL and RETN are used for CALLing subroutines and RETurNing from them. One objectives of subroutines is to avoid having to repeat large chunks of code.
Side-Note: On modern machines and particularly when block-structured languages like Pascal, C, or Modula-2 are used, subroutines via a stack are essential. Older machines often used a JUMP-and-STORE type of call: the return address was stored in a memory address somewhere amongst the code of the subroutine.
That is, we use global variables to pass values to and from the subprogram.
Recall the multiplication program above:
z = x * y;
using the following algorithm:
z = 0;
for(i=1; i<=x; i++){
z = z + y;
}
This is fine, but have a look at the assembly code; it is not the sort of thing you want to be bothered with each time you want to multiply two numbers. The code for the multiply will never change, only the names of the variables (x, y, z).
Say you wanted to do the following:
c = a * b;
d = e * f;
g = c + d;
A simplistic solution would be:
lodd z; stod c;;
startprog:
lodd a (assume at location 200)
stod x
lodd b
stod y
jump mult 204
** lodd z 205
stod c 206
But, without subprograms, the is a major problem: the program never gets to `**', because when it's finished the multiply program it continues on to the next instruction after `mult' (end: i.e. 115H), not 205H as desired.
Note, however, there is nothing to stop you (at 115H) JUMPing to 205 - but this means that `mult' program is only useful for this one multiply; later down at 20aH (say) when we want to multiply `e' and `f', we want to JUMP back to a different place.
This gets us to one of the crucial differences between JUMP and CALL (subprogram). With JUMP, it's a one way ticket, you don't ever come back! With CALL you can remember where you came from and JUMP back there (using RETN) when you're finished in the subprogram.
Figure 7.8 shows how we can make the multiply program into a a procedure `mult' (just add RETN at the end) and how to use it.
Note: there is no explicit use of the stack, all PUSHes and POPs are done implicitly by CALL, RETN.
The procedure `mult' above has no parameters; effectively we used global variables x, y, z for the parameters and return value. In C++ this would look like Figure 7.9.
This is alright, but I'm sure your Programming courses up to now have warned you against the evils of global variables.
So, we now write `mult1' that looks like this:
int mult(int x, int y)
{
return x * y;
}
and is called like: c = mult(a, b);
To do this we need to make explicit use of the stack: we PUSH onto the stack the two values to be multiplied - the arguments, then CALL, finally when we RETN we retrieve (POP) the result from the stack. We can make the multiply program into a proper procedure `mult1' (just add RETN at the end) with parameters and return values, see Figure 7.10. We will also change `mult' slightly to ensure that it uses only two local variables - the only reason for this is to make it a bit more like the one in [Tanenbaum, 1990].
Above, we used the trick of passing the result back in the AC. This is alright for a single 16-bit result, but, if the result was more than one word (e.g. 32-bit floating point stored in two words, or a record), we would have to use the stack.
The usual solution is to allocate space for the return values just before the return address.
Most computers (eg. 80X86, 680X0, VAX) have a multitude of general purpose CPU registers - just as if Mac-1 allowed the assembly programmer access to registers A, B, ...F.
Therefore, as well as storing the return address - which we could term `storing the callers PC', it may be necessary to store these registers as well before going off to a procedure. This is because, inevitably, the procedure will overwrite some or all of the registers and on return, we want to be able to `restore' the registers and carry on where we left off. This pair of processes is called `saving' and `restoring' the 'environment'.
Alternatively, a more common practice is to leave it up to the procedure to save whatever registers it will overwrite - and restore them just before returning.
Here, of course, we are concentrating on subprograms; there is nothing to stop a programmer using the stack as a general temporary storage area, or for a purpose like the swapping mentioned above.
In connection with procedures, there are four uses for the stack:
int a, b, c;
a = 25;
b = 159;
c = mult1(a, b);
a = 0
(*...etc*)
See section 7.9.2 for `mult1' in assembly:
int mult1(int i, j);
The interesting action happens after `b:=159;'.
[sp]<-401f, [401f]<-25;
[sp]<-401e, [401e]<-159;
[sp]<-401d,
[401d]<-210;
Addr. Contents
----- --------
4020 ?
401f 25
401e 159
401d 210 <-- SP (SP now points at 401d)
But we're still not done. We must allocate space for the two local variables on the stack. We could do this by:
loco 0
push
push
i.e. push two zeros onto the stack, but a quicker way is
desp 2
i.e. decrement the SP by 2, in which case the stack looks like
Addr. Contents
----- --------
4020 ?
401f 25
401e 159
401d 210
401c ?*
401b ?* <-- SP (SP now points at 401b)
Note that the space for the local variables is now uninitialised, i.e. 401c and 401b contain whatever was last put in them. This is why you can never assume that a local variable is initialised to 0.
Thus, in general, the stack looks like Figure 7.11. This is called the subprogram's stack frame.
If you called the procedure mult1 recursively three times
- or, indeed, there were three nested calls of different procedures - the
situation would look like Figure 7.12
In this way a procedure can call itself again and again, without one call interfering with the other; the only limit is the size of the stack.
Earlier machines, and languages, like FORTRAN, did not use a stack. Parameter passing, return addresses and local storage was all mixed in with the procedure code area - and there was only one copy - so any recursive calls, if they were allowed, would have overwritten the local data area etc. of the previous call.
i - the counter
in mult1 - was declared globally, you cannot allow recursive calls
to the procedure. Explain why - use a stack-frame diagram if necessary.
pow - see above - recursively. Express the
algorithm in Java and get it working. It should take no more than three or four
lines.
(b) Express the recursive pow algorithm in Mac-1 assembly code.
In the scheme mentioned in the previous two subsections, parameters are
passed by by value, or by copy. Thus, procedure mult1
can do whatever it likes to the memory location that contains the
25 - the copy of a (the parameter) and
a itself (the argument) are separate and so the argument
a - in the caller - will never change.
In Java parameters are, by default, pass by value; in C++ you have reference parameters which are passed by reference. or by access, so that if you change the parameter inside the procedure, that change is reflected outside the procedure. See section 7.2.
The following - from [Tanenbaum, 1990], pages 179-183 - shows a much more realistic example. It shows a complete program, in Pascal. In particular, in contrast to some of our examples, it shows that all local variables reside on the stack. I gives a further example of how to handle arrays.
Insert p. 179 here
! Insert pp. 180-81 here ! !
! Insert pp. 182-83 here ! !
As indicated above, a non-procedure solution could have been used to repeat
the mult code as many times as a multiply was required. As well as
making the program bigger, this would have introduced the greater problem of
three pieces of code to debug/maintain, instead of just one.
Now, if we are content to accept the increase in program size, use of a macro avoids the second problem (i.e. maintenance of separate copies of the same code).
Essentially, you declare a macro containing the working bits of the subroutine (no need for the housekeeping bits at the top and bottom) and then insert the macro code wherever the CALL appears.
Macros are used whenever you want to trade memory for speed - you waste no time PUSHing and POPping the stack; however, avoid if possible - they make a program difficult to read, think about and, consequently, hard to test.
[NB. Mac-1 has no interrupts - the following is modelled on interrupts on the 80X86].
The scheme of polled input and output indicated in sections 7.6.2 and 7.6.3 is fine for many cases, especially if the computer is just reading data from a single source.
However, consider the case of the keyboard and GUI interfaces with a mouse. In Windows and other operating systems the keyboard is read even when the computer is away running another part of the program. This is done with a special type of subroutine call - an interrupt.
When you hit a key on the keyboard, something like the following happens:
[We are now in the interrupt service routine]
A key factor is the transparency of the interrupt. The interrupt causes the service routine to run, but when that routine is finished, and IRET executed, the executing program should be none the wiser - except, maybe, it notices that an instruction took 20 or 30 microsecs to run, instead of just 1 microsec; and, of course, there will be another character in the input buffer.
(a) what is the total time for each interrupt?
(b) estimate the highest interrupt frequency that may occur?
Assume that there are no other generators of interrupts.
Mass storage devices like disk or tape require very rapid data transfer of data from the device to memory and vice-versa. A typical hard disk transfers data at about 1 byte per 2 microsecs (1993); neither polled nor interrupt-initiated input-output could cope with this.
In addition, if you look at the system diagram in Figure 7.13, you will see that both the disk (for example) and memory are connected to the system bus. Hence, there may be little requirement for the CPU to get involved in a data transfer, except to initiate it. Typically, a third device will be connected to the bus - a DMA controller - which mediates between the two data transfer devices and ensures an orderly use of the bus.
In DMA, the only effect on the CPU and executing program is slight slowing down, because the DMA must steal bus cycles -- so called cycle-stealing -- for the data transfer. For example, recalling Mac-1a, and memory read/write: during a LODD, for example, Mac-1a would place the address to be read in MAR, and issue an RD; if a DMA byte transfer was happening, the DMA would have to be able to tell the CPU to wait for a cycle or two.
addr. 20 contains 40 addr. 30 contains 50 addr. 40 contains 60 addr. 50 contains 70 (1) load immediate 20 (2) load direct 20 (3) load indirect 20 (4) load immediate 30 (5) load direct 30 (6) load indirect 30
Assume that there are other generators of interrupts.
6. Explain how an INDEX register may assist in the handling of arrays; use as an example the case where you wish to add 3 to the array of 10 numbers starting at address 500.
7. Multiplication etc.
(x + y * z) and returns the result in the AC.
Assume you can Call `mult1', as described in the notes text, to do the
multiplication.
w = mpyadd(x, y, z);
c = 45H; error = outch(c,1000);
error = write4(a,b,c,d);.