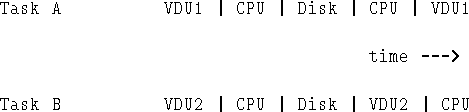 |
In Chapter 8 we saw how the operation - in the sense of `driving' them - of computers evolved through users operating them, to operators, and finally through various sophistications of operating system software to timesharing operating systems.
First, we give a demonstration of the effect of multiprogramming.
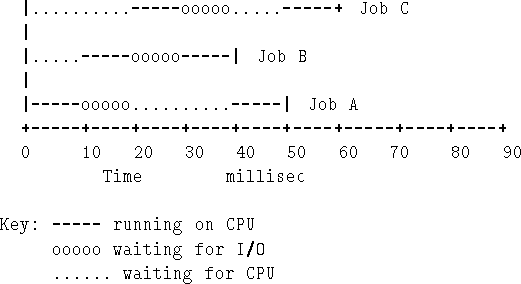
Figures 9.1 and 9.2 shows the execution of three identical jobs, under two different operating system regimes.
Assume that the jobs/processes/programs are in memory to start with, that they do some computation (taking 10 millisec) which results in the requirement to read a particular record from a disk file (taking 10 millisec), finally they do some more computation (again 10 millisec). Viewed as executions of single programs this may not appear too useful - where do the results go to - but, in fact, the jobs are quite typical of what would be encountered by a timesharing during the execution lifetime of three processes
Figure 9.1 shows how the jobs would have to run on a single user system like MS-DOS. The computer is I/O blocked during each disk input - regardless of whether the input is by polled I/O, interrupts, or DMA.
Figure 9.2 shows the effect of multiprogramming; when one process become I/O bound, the CPU can do processing for another. Thus, a 90 millisec of computer usage can be reduced to 60; add more jobs and you get a greater increase in efficiency. NB. in this case, you are concerned with the method of I/O transfer - ideally the CPU asks for the data, and receives an interrupt when they are placed in memory.
The work that a modern timesharing operating system performs is a good deal more complex than that of, for example, a simple resident monitor - or even a single user OS like MS-DOS. Nevertheless, like all complex systems, the analysis of operating systems responds to breaking them into subsystems/components.
The following functions are required:
The functions that meet these requirements, and the relationships between them are sometimes shown as a so-called onion-skin diagram; this concept of layers of skin is closely related to that of levels of abstraction given in chapter 8.
We shall now briefly look at a selection of topics that pertain to these requirements.
The concept of a process is central - first used by MULTICS. Sometimes referred to as a task. Definition can be difficult: `a program in execution' may be the best.
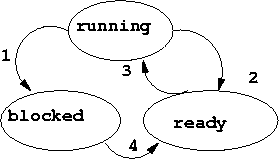
During its life, a process goes through a series of discrete states:
When a job is admitted to the system, a corresponding process is created and placed at the back of the queue and it is marked ready; alternatively, there may be separate queues. It gradually moves to the top of the ready list - see scheduling/dispatching below; when the CPU becomes available the process makes a state transition from ready to running. Strictly speaking this is dispatching.
To prevent any one process, say process A, monopolising the system - i.e. to provide time-sharing it must be possible possible to stop the process after it has consumed its allocated amount of CPU time. This is done via an interrupting clock (hardware) which allows a specified time quantum - a time-slot to pass; if process A is still using the CPU the clock generates an interrupt, causing the system to regain control. Process A now makes the state transition back to ready, i.e. A is put back in the ready queue.
The next process, process B, say, on the ready queue is now put into the running state; and so on ....
If a running process initiates an I/O operation before its time-slot expires then the process is forced to release the CPU; it enters the blocked state and releases the CPU.
If a process is in the blocked state and the event for which it is waiting completes, then the process makes the transition from blocked to ready. The four state transitions are shown in Figure 9.3
Because of this `switching on and off' of processes is is necessary to have housekeeping information associated with each process. A process control block PCB which is a record containing important current information about the process, for example: current state of the process, unique identification of the process, the process's priority, open files & I/O devices, use of main memory and backing store, other resources held, a register save area (see chapter 7).
All of the operations involving processes are controlled by a portion of the OS called its nucleus, core or kernel. The kernel represents only a small portion of the code of the entire OS but it is intensively used and so remains in primary storage while other portions may be transferred in and out of secondary storage as required.
One very important function of the kernel is interrupt processing. In large multi-user systems, the kernel is subjected to a constant barrage of interrupts. Clearly, rapid response is essential: to keep resources well utilised, and to provide acceptable response times for interactive users.
In addition, while dealing with an interrupt, the kernel disables other interrupts. Thus, to prevent interrupts being disabled for long periods of time, the kernel is designed to do the minimum amount of processing possible on each interrupt and to pass the remaining processing to an appropriate system process.
The kernel of a sophisticated OS may contain code to perform:
Supporting hardware and microcode is often provided - even for portable operating systems like UNIX.
The kernel has privileges that allow it to do things that normal processes cannot do, e.g. access I/O devices. Privilege is usually conferred by the processor state, i.e. privilege level is stored in hardware, so a process has a different processor state from the kernel. In the original Intel 8086/88 and 80286, there was limited support for processor states; however, in the 80386 and after, full time-sharing was supported.
The goal of scheduling (the method by which processor time is managed) is to provide good service to all the processes that are currently competing for resources, including the CPU.
Three type of scheduling may be identified: long term scheduling, medium term scheduling, and short term scheduling.
We will be concerned only with short-term scheduling - also called dispatching, which decides how to share the computer among all the processes that currently want to compute. Such decisions may be made frequently - tens of times per second.
There are several competing goals that scheduling policies aim to fulfill - one is good throughput. For short term scheduling, this minimizes the number of process switches. Another goal is good (quick) service.
Some of the - often conflicting - objectives of a good scheduling algorithm/policy are:
Thus, scheduling may appear to be a complex problem.
Under FCFS, the short term scheduler runs each process until it either terminates or leaves because of I/O or resource requests. Processes arriving wait in the order that they arrive.
FCFS is non-preemptive, so a process is never blocked once it has started to run until it leaves the domain of the short term scheduler.
FCFS is usually unsatisfactory because of the way that it favours long (greedy) processes - like the person in the bank queue in front of you with the weeks takings from a shop!
The intention is to provide good response ratios for short as well as long processes. This policy services (allocates CPU to) a process for a single time slot (length = q), where q = between 1/60 and 1 second; if the process is not finished it is interrupted at the end of the slot and placed at the rear of the ready queue & will wait for its turn again. New arrivals enter the ready queue at the rear.
RR can be tuned by adjusting q. If q is so high that it exceeds the service requirements for all processes, RR becomes the same as FCFS. As q tends to 0, process switching happens more frequently and eventually occupies all available time. Thus q should be set small enough so that RR is fair but high enough so that the amount of time spent switching processes is reasonable.
RR is preemptive, i.e. it will stop a process, if the process has not completed before the end of its time-slot.
SPN (like FCFS) is non-preemptive. It tries to improve response for short processes over FCFS. But, it requires explicit information about the service time requirements for each process. The process with the shortest time requirement is chosen.
Unfortunately, long processes wait a long time or suffer starvation. Short processes are treated very favourably.
Figure 9.4 shows a five level storage organisation.
Data that is currently accessed most frequently should be in the highest level of storage hierarchy. Each offers about an order of magnitude faster access than its lower neighbour.
The relationship between each layer and the one below it can be considered as similar to that between cache and main memory - cache explained during tutorial or see a textbook. If we need to cache an item from a higher level then access is significantly slower. We call such a situation a cache miss. In contrast a cache hit is when we find the data we need in a cache and need not turn to the associated slower memory.
The OS must arrange main memory so that processes remain ignorant of each other and still share main memory. A guiding principle is that the more frequently data are accessed, the faster the access should be. If swapping in and out of main storage becomes the dominant activity, then we refer to this situation as thrashing.
Physical store is the hardware memory on the machine, usually starting at physical address 0. Certain locations may be reserved for special purposes; the kernel may reside in in the low addresses. The rest of physical store may be partitioned into pieces for the processes in the ready list.
Each process has its own virtual memory - the memory perceived by the process. As far as the process is concerned all address references refer to virtual space. Each process' virtual memory is limited only by the machine address size.
Note: Virtual memory can also be very useful even in a single user system - if the computer has a larger address space than physical memory, and if programs need a large amount of memory; compare overlaying - in which the programmer takes responsibility for segmenting the program into memory sized chunks.
The following, from [Tanenbaum, 1999], pages 65-67, gives a nice explanation of cache memory; cache memory is a small amount of fast memory near the CPU which in many cases mitigates the difficulties caused by the slow(ish) speed of main memory and by the bottleneck of MAR, MBR (see chapter 5). The basic principles employed in paging, see section 9.9, apply to caching.
Insert p. 65 here.
!Insert pp. 66, 67 here ! !
The most common virtual storage technique is paging. Paging is designed to be transparent to the process - like all virtual memory.
The program and data of each process are regarded - by the OS as being partitioned into a number of pages of equal size. The computer's physical memory is similarly divided into a number of page frames. Page frames are allocated among processes by the OS At any time, each process will have a few pages in memory, while the remainder is in secondary memory.
The real point behind paging is that, whenever a process needs to access a location that is within a page that is in secondary memory, the page is fetched, invisibly to the process, and the access takes place, almost as if the datum had already been in memory. Thus, the process thinks that it has ALL of its virtual memory in main memory.
The remainder of this discussion can now proceed as if we are only concerned with a single process, which happens to be using a bigger virtual memory than can fit in main, physical, memory; ie. what is said is applicable to single user systems as well as multi-user. In addition, we shall simplify the arithmetic by assuming a page size size of 1000 - simpler for decimal oriented humans.
The process's virtual memory is divided into pages. Page 0 refers to locations 0 to 999, page 1: 1000 to 1999, and so on, ...
The CPU must transform from virtual address to physical address:
The third column - Secondary Store address - indicates where the OS must read/write if a page is to be transferred in/out of memory.
If the process needs a page which is not in memory - marked by a -1, for example-- a page fault is generated, and the OS sets about reading the required page into main memory. Obviously, some other page will have to be removed, to make space for the new page.
The whole paging process is illustrated by the pseudo-code in Figure 9.6.
Think of PagedVirtualMemory being used in the situation where you
have a PC with 32-bit addressing - 2 Gigabytes of virtual memory) but only 2K of
physical memory available for data - forget about instructions for this example.
Imagine that you want to use a 60K array of bytes. You use
PagedVirtualMemory to access the array; the function hides all the
hassle of address translation and paging.
The choice of page size determined at the design stage is a trade- off between various considerations:
Larger pages are usually better, unless they become so large that too few processes in the ready list can have pages in main store at the same time. Common page sizes are from 512 bytes to 4K bytes but can be as large as 8K.
The storage manager must decide to keep some pages in main store and other pages in secondary store - unless virtual space requirements are less than the available physical space.
These decisions may be made at any time but when a page fault occurs a decision must be made; the process that suffered the page fault cannot continue until the appropriate page is swapped in.
A page replacement policy (PRP)/algorithm is used to decide which page frame to vacate ie. swap out its page.
Some commonly quoted strategies are:
Note: pages being heavily used should be preserved. One goal is to minimize the number of page faults. Swapping can reach a level at which all processes present need to swap so no progress can be made. If this persists, the OS is spending all its time transferring pages in and out of main store - known as thrashing.
Also called longest resident.
When a page frame is needed, the page that has been in main store for the longest time is chosen. This policy tends to save recently used pages which have a higher probability of being used again soon. However a frequently used page still gets swapped out when it gets to be old enough, even though it will have to be brought in immediately.
This method is based on the assumption that the page reference pattern in the recent past is a mirror of the pattern in the near future. Pages that have been accessed recently are likely to continue to be accessed and ought to be kept in main store. It is expensive to implement exactly since in order to find the page least recently used, either a list of pages must be maintained in use order or each page must be marked with the time it was last accessed.


![\begin{figure}\begin{tex2html_preform}\begin{verbatim}byte PagedVirtualMemory(in...
...return byte at aa; //i.e. M[aa]}\end{verbatim}\end{tex2html_preform}\end{figure}](img383.gif)